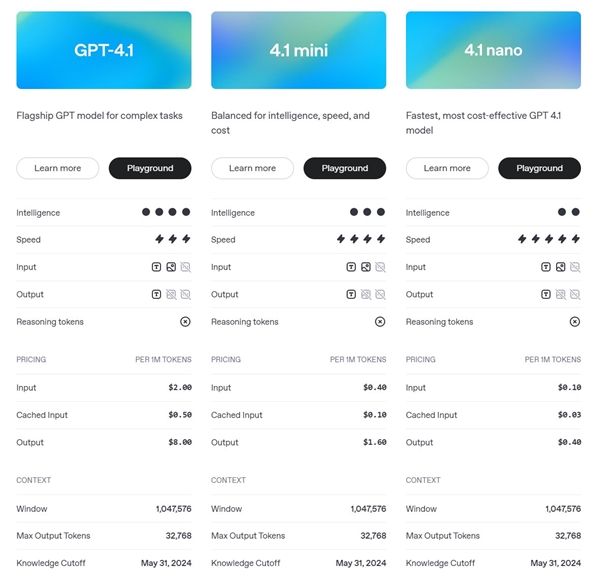
Early this morning, OpenAI officially released the GPT-4.1 series model, bringing three models, the standard version of GPT-4.1, the lighter and faster GPT-4.1 mini and the ultimate cost-effective GPT-4.1 nano, which comprehensively surpasses GPT-4o and is smarter and cheaper.
Currently, the GPT-4.1 series is only available through the API and is now open to all developers.
Compared with previous models, GPT-4.1, GPT-4.1 mini and GPT-4.1 nano can handle up to 1 million tokens, 8 times that of GPT-4o.
OpenAI benchmarks show that the GPT-4.1 series scores more than the GPT-4o and GPT-4o mini in terms of encoding, instruction compliance, and long text understanding.
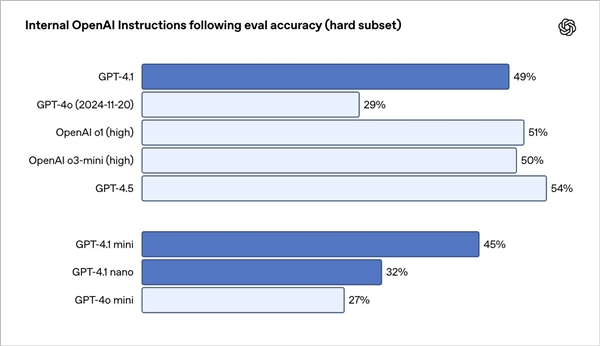
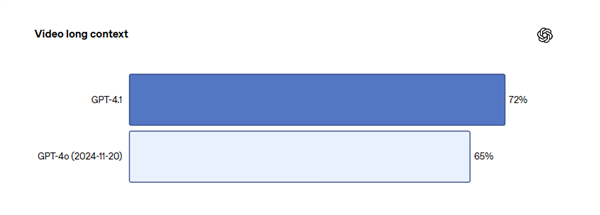
It is understood that GPT-4.1 scored 54.6% in the programming test SWE-bench Verified, an increase of 21.4 percentage points from GPT-4o, an increase of 10.5 percentage points in the instruction compliance test MultiChallenge, and a record of 72.0% in the multimodal long text test Video-MME.
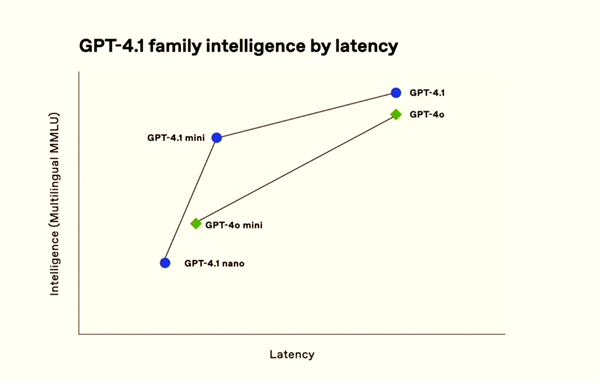
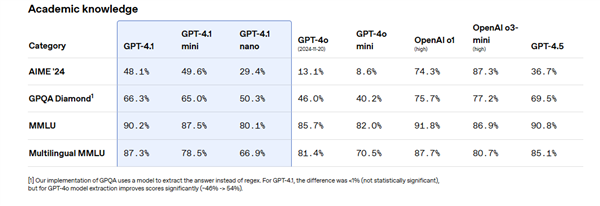
GPT-4.1 nano is the fastest and cheapest model for OpenAI to date. Although it is small, it has excellent capabilities. The benchmark MMLU score is 80.1%, the GPQA score is 50.3%, and the Aider multilingual encoding score is 9.8%, both higher than the GPT-4o mini, suitable for scenarios that require low latency.
It is reported that the GPT-4.1 input fee is US$2 per 1 million tokens and the output fee is US$8 per 1 million tokens. For medium-sized queries, the price of GPT-4.1 is 26% lower than that of GPT-4o.